
Indexation et recherche des candidats
Cet article fait partie d’une série d’articles sur la recherche dans de gros volumes de données à travers l’utilisation des technologies récentes de Deep Learning. Introduction de la série.
Une fois les entreprises encodées sous forme de vecteurs, il reste la question de la recherche. Comment trouver les vecteurs les plus similaires à celui de la requête parmi l’ensemble des vecteurs des entreprises ?
Comme on l’a vu précédemment, si le nombre de vecteurs dans lequel il faut rechercher est vraiment grand, des problématiques se posent quant à la manière de les stocker et d’exécuter la requête pour obtenir des temps de réponses raisonnables.
L’approche basique appelée recherche des “k plus proches voisins” consiste à calculer la distance (pour nous le produit scalaire) entre le vecteur de la requête et les vecteurs de toutes les entreprises pour trouver les plus similaires.
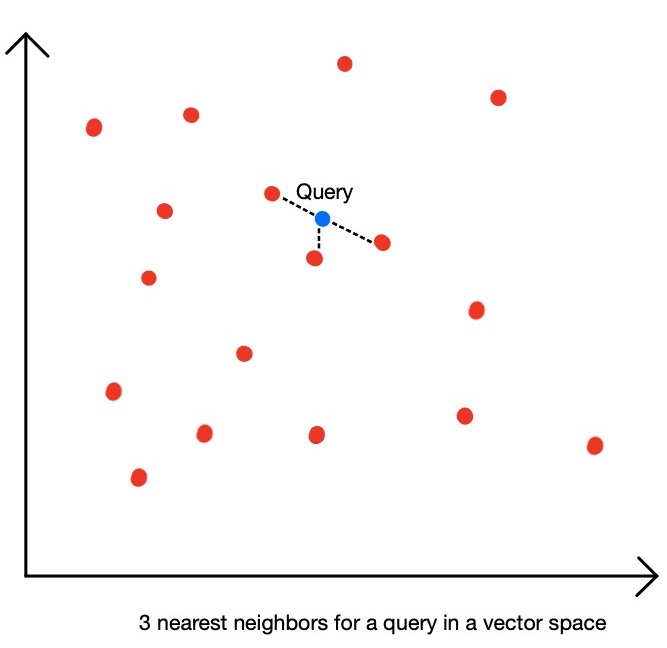
Le souci est que l’on calcule la distance avec l’ensemble des vecteurs du datalake donc cette approche peut rapidement devenir trop lente si le datalake a une taille importante. C’est pourquoi en général, on préfère approximer la recherche afin de l’accélérer. Au lieu de comparer avec l’ensemble des vecteurs, on va essayer de se limiter aux vecteurs les plus pertinents et ainsi réduire le nombre de calculs à exécuter. Une recherche approximée est généralement bien plus rapide qu’une recherche exhaustive (de plusieurs ordres de grandeur), mais elle entraine une perte de precision. C’est-à-dire que l’on risque de rater certains vecteurs.
On ne va pas aborder l’ensemble des méthodes et des algorithmes autour de l’indexation et recherche de vecteurs, car il s’agit d’un domaine à part entière d’une grande complexité et encore très actif. Cependant, on va discuter des approches principales les plus fréquemment utilisées.
D’un point de vue technique, de nombreuses bibliothèques de recherche approximée de vecteurs se développent, les plus utilisés étant probablement Faiss, nmslib (avec hnswlib) et Annoy. Nous avons retenu la bibliothèque Faiss car c’est la bibliothèque la plus populaire et vraisemblablement la plus complète. La terminologie que nous allons utiliser par la suite est donc celle de Faiss (il peut y avoir quelques différences suivant les bibliothèques).
Comme évoqué plus tôt, l’objectif de la recherche approximée de vecteur est de réduire le temps de recherche lorsque l’on a de gros volumes de vecteurs. Les deux approches principales que nous allons aborder se basent sur le partitionnement de l’index pour l’une et sur la construction d’un graphe hiérarchique pour l’autre.
L’approche par partitionnement découpe l’espace des vecteurs en sous parties (on parle techniquement de cellules de Voronoï). Ensuite, lorsque l’on effectue une recherche, on peut se focaliser sur la cellule la plus pertinente et donc réduire le nombre de calculs nécessaires. On nomme ce type d’index IVF, pour Inverted File Index.
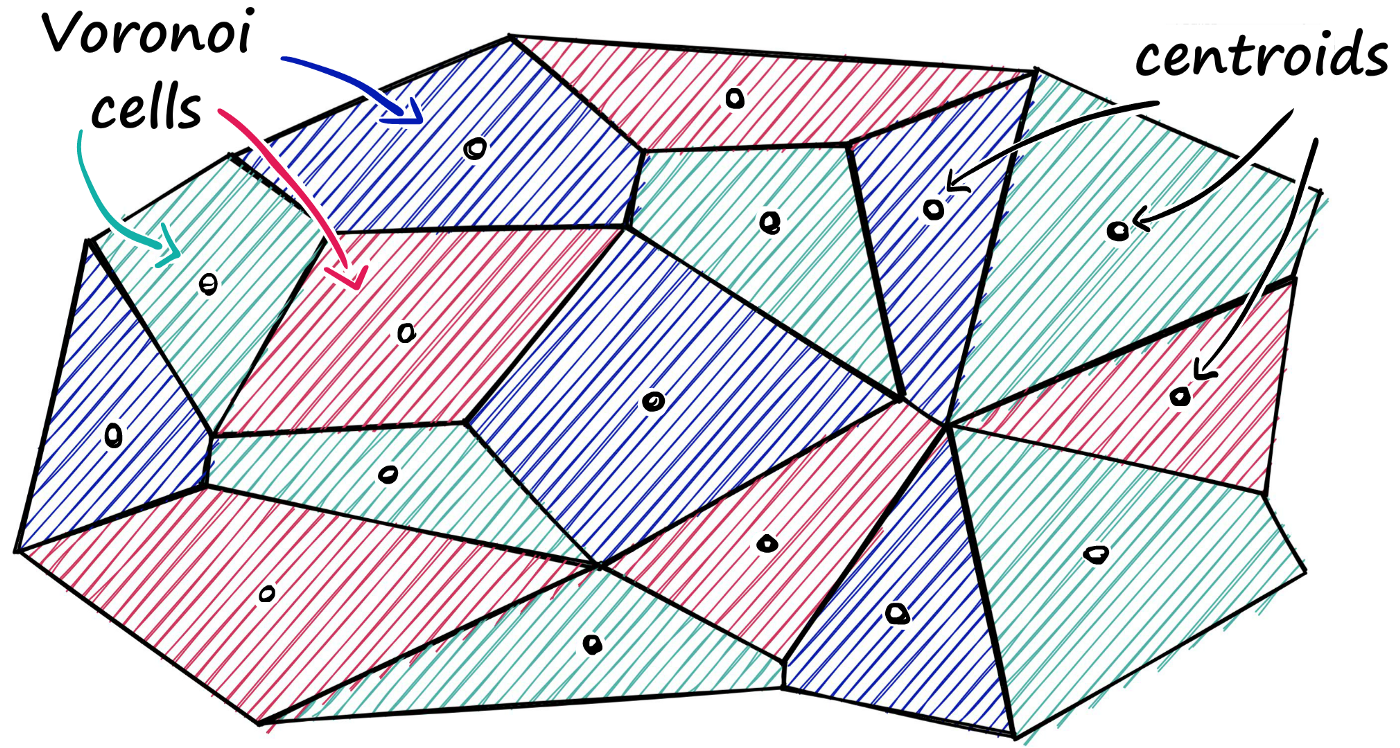
Il y a plusieurs approches possibles pour découper l’espace, mais la plus simple consiste à effectuer un clustering K-Means des vecteurs. Avec cette approche, des erreurs sont possibles, autrement dit, on peut rater des vecteurs pertinents. En effet, si on cherche un vecteur en particulier, mais que l’on se focalise sur la mauvaise cellule, il ne sera pas possible de trouver ce vecteur. La précision d’un index représente le pourcentage d’erreurs (ou de vecteurs ratés) que l’on aura avec cet index. Par défaut un index IVF aura une précision relativement faible. En effet, tous les vecteurs proches d’une frontière de partition sont potentiellement à risque. On peut cependant limiter ce phénomène en parcourant plusieurs cellules plutôt qu’une seule. Mais cela aura un impact sur le temps de recherche. Plus on parcourt de cellules et plus la requête sera longue. Si on pousse le résonnement à l’extrême et que l’on parcourt toutes les cellules, alors cela revient à faire une recherche exhaustive classique.
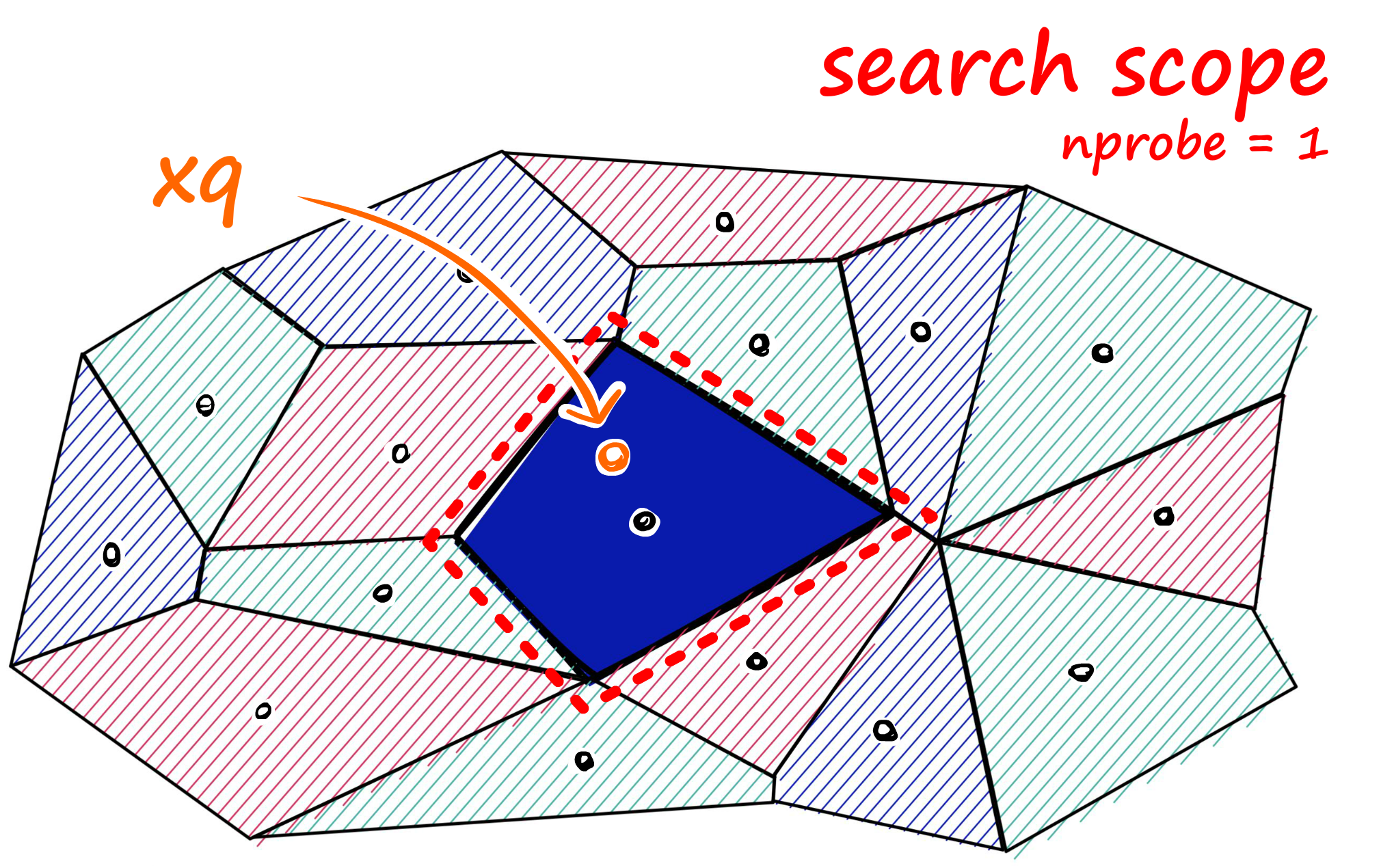
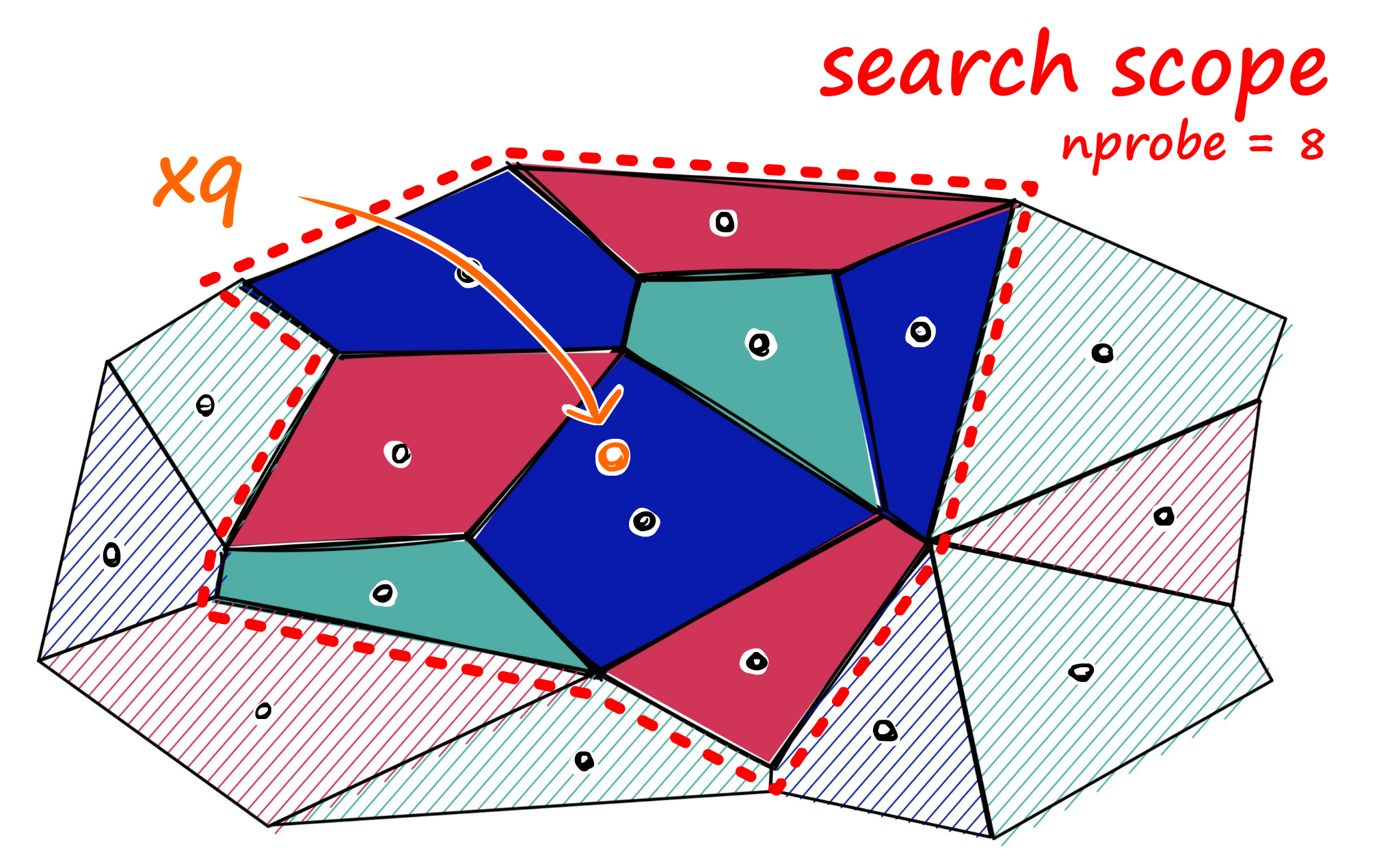
On se rend compte que cette méthode présente différents paramètres (principalement le nombre de cellules à créer lors
du découpage de l’index et le nombre de cellules à parcourir lors de la requête) avec lesquels il va falloir jouer
pour trouver un compromis entre le temps de réponse et la précision de l’index.
Toutes les approches de recherche approximée présentent ainsi des paramètres et des compromis différents.
Il faut noter que la création d’un index IVF nécessite un apprentissage pour trouver le partitionnement de l’espace.
En général, il s’agit de l’apprentissage d’un clustering K-Means.
Cet apprentissage est dépendant du nombre de vecteurs et peut donc être assez long.
Avec Faiss, il peut être effectué sur GPU.
L’autre approche principale se base sur un graphe hiérarchique pour représenter l’index. On appelle ces index HNSW (Hierarchical Navigable Small Worlds).
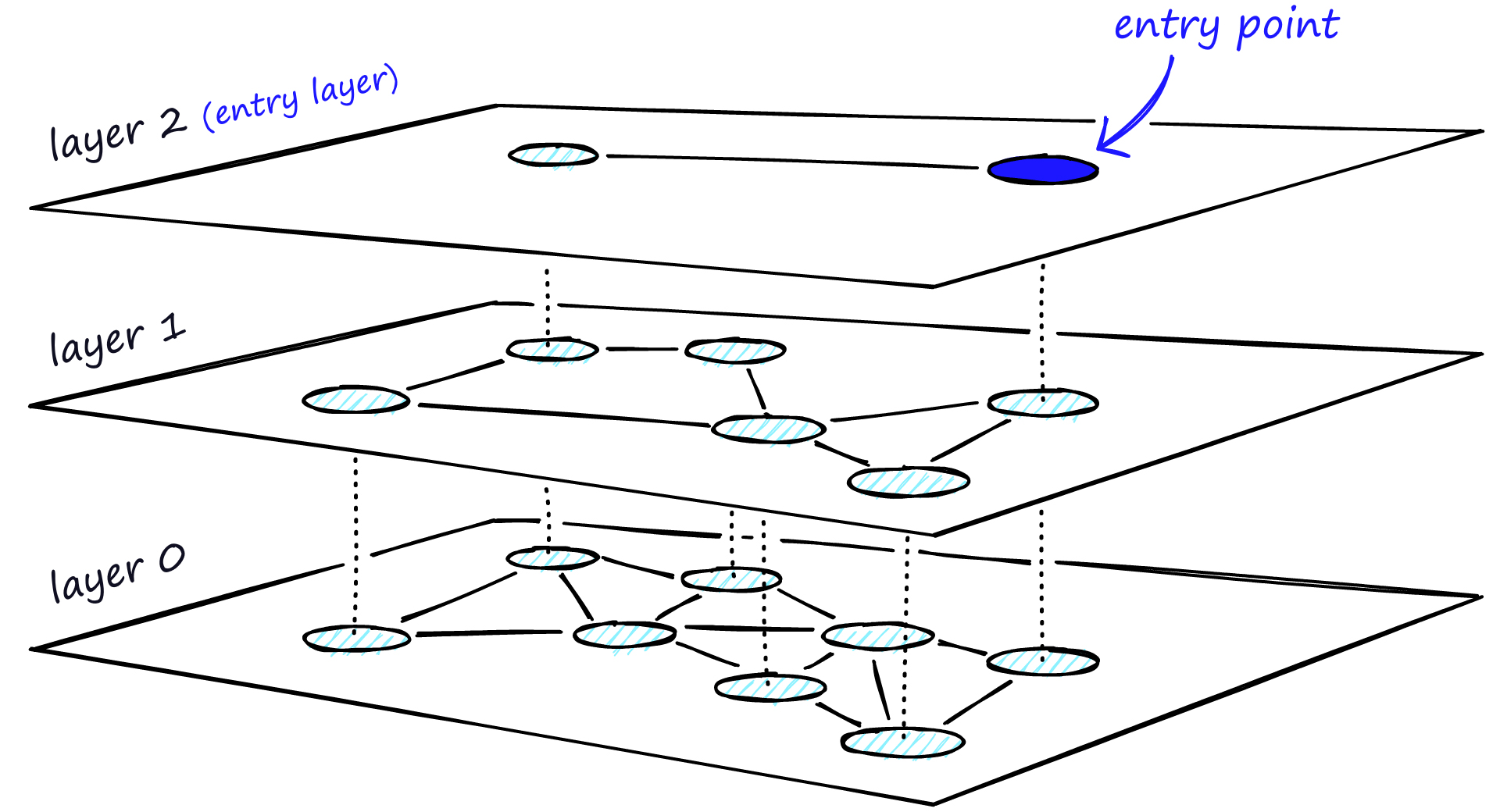
Cette approche donne de très bons temps de réponse ainsi qu’une très bonne précision. Cela semble donc répondre à tous nos besoins. Malheureusement, il reste une dimension dont on a n’a pas encore parlé : la mémoire nécessaire pour stocker l’index. En effet, les index Faiss sont stockés en RAM. Plus les index consomment de mémoire, plus ils nécessitent de grosses machines et donc plus cela coûte cher. De plus au-delà d’un certain nombre de vecteurs la quantité de RAM nécessaire peut devenir tellement importante que l’approche HNSW n’est plus vraiment viable. C’est donc une approche que l’on garde pour les cas d’usages avec un nombre de vecteurs limités (jusqu’à quelques millions).
Ainsi en parallèle du choix de la méthode d’indexation (IVF ou HNSW par exemple) on va pouvoir ajouter une étape pour réduire la place prise par nos vecteurs en mémoire. Encore une fois, il y a plusieurs approches possibles, les principales étant la réduction de dimension et la quantization des vecteurs.
La réduction de dimension bien connue en Machine Learning consiste comme son nom l’indique à diminuer le nombre de valeurs dans un vecteur. Si en sortie de modèle de langage, nos vecteurs ont une dimension de 768, l’idée va être de réduire cela à 128 ou 64 par exemple. La méthode la plus connue pour réduire les dimensions d’un vecteur est l’ Analyse en Composantes principales (ACP). Il est donc possible avec Faiss de réduire les dimensions de nos vecteurs grâce à une ACP avant de les indexer avec un IVF par exemple. Mais en pratique ce n’est pas l’approche la plus fréquemment utilisée puisqu’une autre solution donne généralement de meilleurs résultats.
Il s’agit de la quantization. Son principe consiste à réduire la plage de valeurs que peuvent prendre les dimensions d’un vecteur. Par exemple, pour un vecteur classique chaque dimension est représentée en Float32, c’est-à-dire avec 32 octets. Cette representation permet d’encoder beaucoup de valeurs différentes possibles et donc d’avoir des vecteurs très précis. Seulement dans la majorité des cas, cette grande précision n’est pas nécessaire pour nos calculs de recherche. On peut ainsi encoder nos vecteurs en Float16 (avec 16 octets) avec un impact minimal sur le résultat de la recherche, mais en divisant par deux la mémoire nécessaire pour stocker les vecteurs. Cette approche est notamment utilisée pour l’apprentissage et l’inférence des gros réseaux de neurones. Dans Faiss on appelle cela Scalar Quantization ou SQ.
On peut cependant aller beaucoup plus loin dans la compression des vecteurs avec ce qu’on appelle la Product Quantization (PQ). L’objectif est le même, réduire la plage de valeur des vecteurs. L’idée est assez simple : on découpe les vecteurs en un certain nombre de sous-vecteurs plus petits. Pour chacun de ses sous-vecteurs, un clustering est effectué et on remplace les valeurs du sous vecteur par l’identifiant du cluster déterminé, réduisant ainsi de beaucoup la quantité d’information. Cette approche PQ permet de compresser les vecteurs de façon très importante jusqu’à atteindre 98% de compression dans certains cas. Pour découvrir plus en détail cette approche, vous pouvez aller voir cet article.
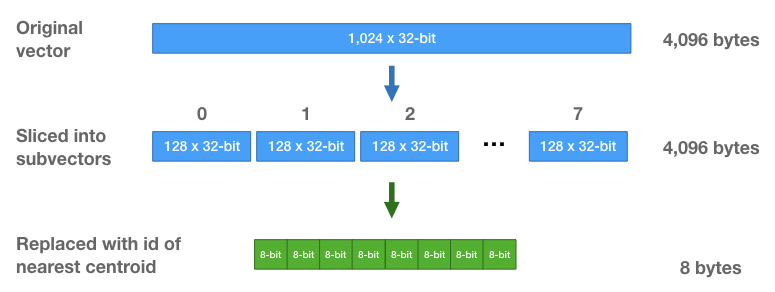
Cependant, il n’y a pas de magie, qui dit compression de l’information, dit approximation de la recherche. Les approches de quantization font ainsi baisser la précision des index. Encore une fois, il faut jouer avec les différents paramètres des quantizers pour trouver un compromis satisfaisant entre la mémoire nécessaire pour stocker les vecteurs, la précision de l’index ainsi que le temps de réponse.
Il est possible de combiner les méthodes d’indexations avec les méthodes de compressions pour ainsi obtenir des index
vraiment performants.
Toutes les combinaisons ne sont cependant pas pertinentes.
Une approche très classique consiste à combiner un index IVF avec un Product Quantizer.
On nomme le tout IVFPQ tout simplement.
C’est l’approche que nous avons retenu pour indexer nos vecteurs d’entreprises.
Elle est très performante en termes de vitesse de requêtage et de quantité de RAM nécessaire, par contre la precision
peut baisser fortement si la quantization est trop forte et si on ne parcourt pas assez de cellules.
Pour notre cas d’usage, la précision est très importante, dans l’idéal, on voudrait qu’elle soit à 100 %,
c’est-à-dire ne jamais rater de vecteurs d’entreprise.
C’est pourquoi nous avons « tuné » les paramètres pour avoir la meilleure précision possible dans les limites
de temps de réponse et de RAM que l’on s’était fixés.
Il faut savoir qu’il est possible d’aller encore plus loin avec Faiss en créant des index composites. Par exemple, on peut mettre en place des index qui utilisent à la fois IVF et HNSW. Avec ce genre d’approches, Faiss peut supporter de la recherche sur des index avec des milliards (voir des billions d’après la doc) de vecteurs. Si le besoin est là il est ainsi possible d’aller très loin dans la complexité d’indexation. Cependant, tester les paramètres des différentes approches prend beaucoup de temps, car l’apprentissage et la construction des index peut être assez longue. Surtout si on a beaucoup de vecteurs, la création d’un index peut prendre jusqu’à plusieurs heures (même en effectuant l’apprentissage de l’index sur GPU). Plutôt que de chercher la solution d’indexation optimale, on a donc préféré s’arrêter quand on a trouvé une solution satisfaisante. Même s’il est probable qu’une meilleure solution existe.
Nous venons de voir comment choisir des index Faiss adaptés en fonction du besoin. Il reste cependant encore des briques à mettre en place pour obtenir un système de recherche complet. En effet, un besoin classique est de pouvoir effectuer une recherche tout en filtrant les résultats selon un critère quelconque. Par exemple pour notre cas d’usage, il est fréquent de vouloir exécuter la recherche sur les entreprises d’une seule région, ou d’un seul département.
Or, ce cas d’usage n’est pas simple à gérer avec notre système actuel. En effet, les algorithmes d’indexations rendent complexe l’execution de la recherche et le filtrage des vecteurs en une seule et même étape (et en gardant un temps de réponse raisonnable).
Deux approches existent pour contourner ce problème:
- le Pre-filtering, qui consiste à filtrer les vecteurs d’entreprises qui nous intéressent avant de faire la recherche,
- le Post-filtering, qui consiste à filtrer les vecteurs après avoir effectué la recherche .
Ces deux approches présentent cependant chacunes des inconvénients.
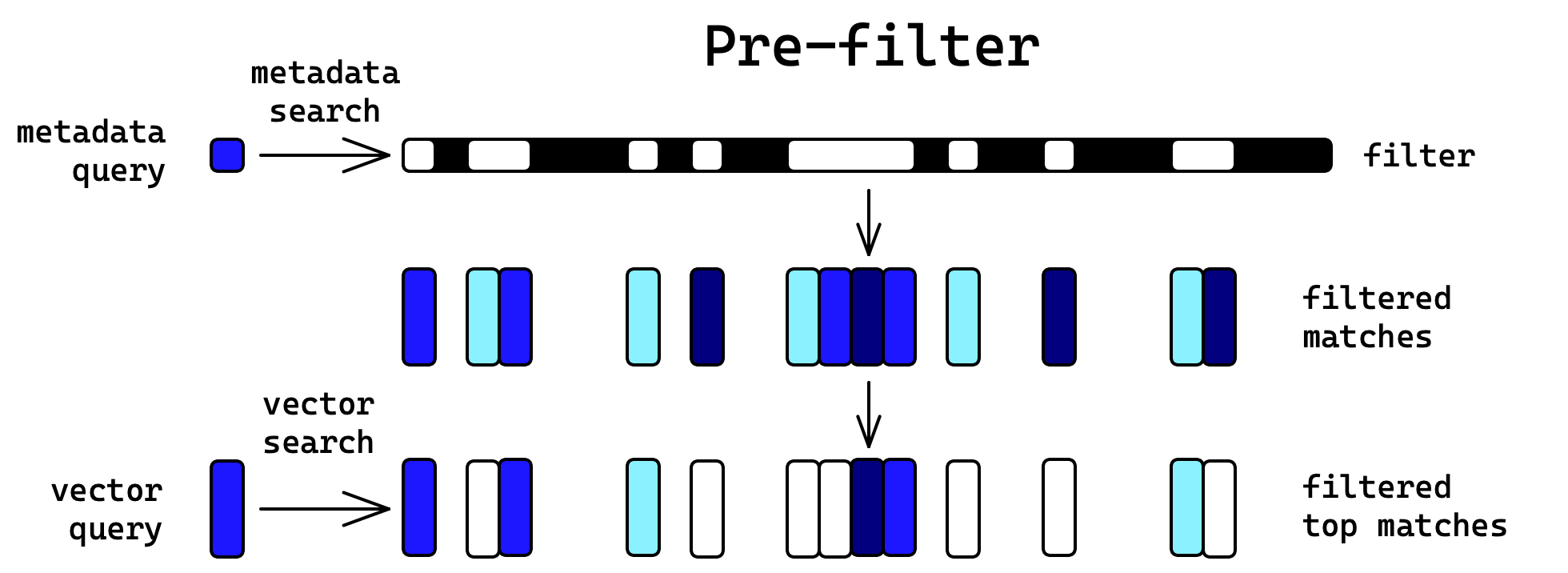
Le post-filtering, qui consiste à filtrer les résultats après la recherche Faiss est donc en général plus intéressant.
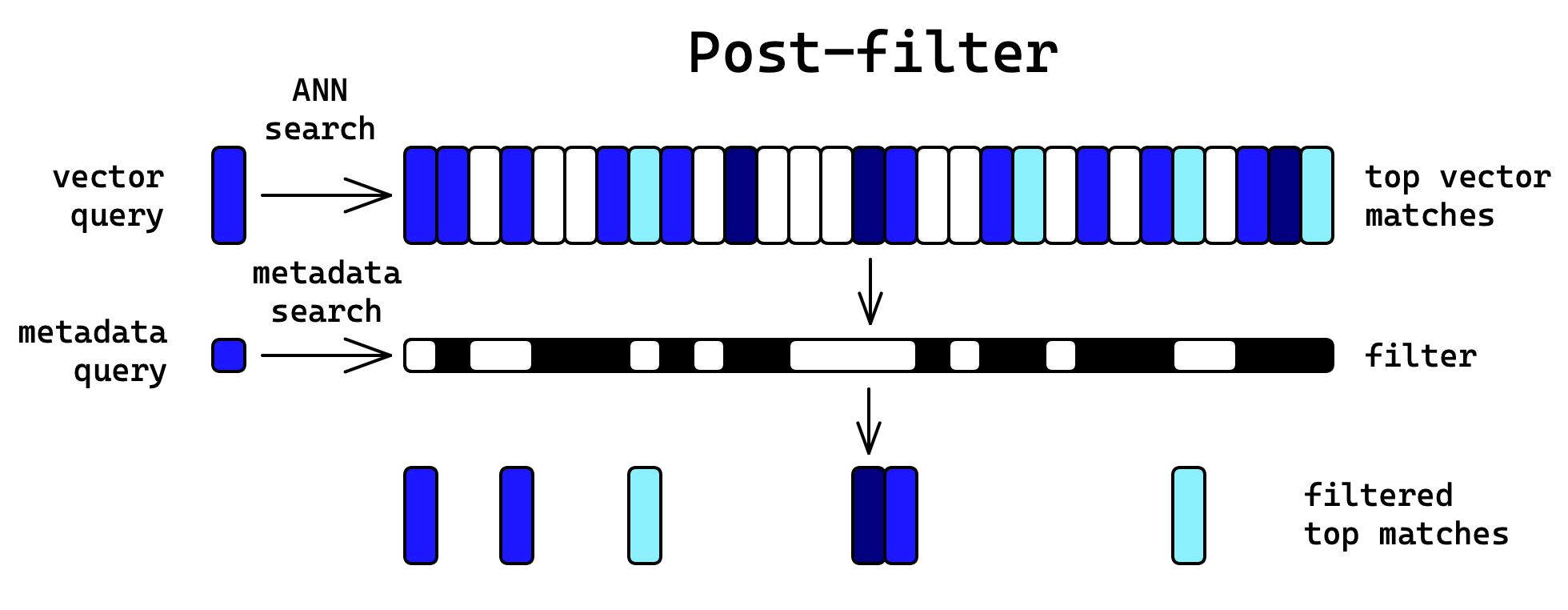
Concernant le filtrage des vecteurs, après la mise en place de notre projet, une nouvelle fonctionnalité qui aurait pu nous simplifier la vie a été implémentée au sein de la bibliothèque Faiss. Il s’agit de la possibilité d’effectuer une recherche dans une sous-partie de l’index en fournissant les identifiants des vecteurs à considérer (voir ici). Cette fonctionnalité semble répondre au besoin de recherche avec filtrage métier. L’idée est de déterminer en amont de la requête les identifiants des entreprises à garder et de les fournir à Faiss au moment de la requête. C’est une piste qui semble très intéressante, cependant, nous avons fait quelques tests rapides et les performances semblent assez fortement impactées. Quoi qu’il arrive, il est probable que cette fonctionnalité soit implémentée dans de plus en plus de bibliothèques de recherche par vecteur, car elle est importante pour rendre ces outils plus simples à mettre en place.
Actuellement, mettre en place un système de recherche par similarité de vecteur demande un investissement conséquent.
Comme vu précédemment dans cet article, il y a déjà un travail à faire pour déterminer la structure d’index
la plus adaptée en fonction du besoin.
Mais surtout, les index eux-mêmes étant des structures de données très bas niveau, pour pouvoir les utiliser au sein
d’un produit, il faut mettre en place tout un environnement autour.
Par exemple, il faut prévoir un système pour faire le lien entre les vecteurs dans l’index Faiss et les données
originales présentes dans une autre base de données.
Il faut mettre en place un système de pre ou post filtering.
Dans le cas où plusieurs index sont utilisés (ce qui est notre cas comme on l’a vu dans l’article précédent),
il faut prévoir le système d’agrégation des résultats, etc.
Les index Faiss ne sont donc finalement qu’une seule des briques nécessaires pour construire un système de recherche
de vecteur.
Une fois la pipeline complète mise en place, nous nous sommes aussi rendus compte que le temps de recherche effectif dans Faiss était négligeable par rapport au reste (récupération des données, aggregations des résultats, etc.). Pour la plupart des usages, il n’est donc probablement pas nécessaire de se focaliser en premier lieu sur les temps de réponses de l’index Faiss. Comme on l’a vu dans cet article, de nombreuses optimisations de l’indexation sont possibles si c’est le temps de réponse de Faiss qui devient limitant. Pour notre projet, la gestion de la mémoire et de la précision de l’index a été bien plus importante.
Pour résumer, l’approche par similarité de vecteurs est une alternative très intéressante aux moteurs de recherche classique tel qu’ElasticSearch mais l’environnement n’est pas encore très mature. Il y a encore beaucoup d’ingénierie « manuelle » et de développement expérimental à faire.
C’est pourquoi de nouvelles solutions techniques commencent à apparaitre : les bases de données de vecteurs.
Il s’agit de surcouches aux algorithmes et bibliothèques de recherche de vecteurs comme Faiss qui permettent
d’abstraire une bonne partie de la complexité.
On peut citer par exemple
Milvus,
Pinecone
,
Weaviate ou encore
Vespa.
Il semble probable que ces Bases de Données de vecteurs se développent de plus en plus dans le futur.
En effet, elles sont un complément logique des réseaux de neurones et du Deep Learning.
Pour notre projet, nous avons décidé de pas utiliser ces bases de données de vecteurs, car aucune ne semblait encore
répondre à l’ensemble de nos problématiques.
Par contre, ce sont clairement des technologies à suivre de très près.
Nous avons vu jusqu’ici comment mettre en place un système de recherche de vecteurs pour obtenir un certain nombre de candidats pertinents. Il ne reste plus désormais qu’a scorer ces candidats à l’aide d’un modèle de Machine Learning pour déterminer le meilleur candidat. Cette étape sera détaillée dans l’article suivant sur le scoring des candidats
Série d'articles sur la recherche d'entreprise
- Introduction
- Sélection des candidats (Retrieval)
- Scoring des candidats
- Conclusion