
Représentation des entreprises
Cet article fait partie d’une série d’articles sur la recherche dans de gros volumes de données à travers l’utilisation des technologies récentes de Deep Learning. Introduction de la série.
Dans cet article, nous allons voir comment utiliser les modèles de langages pour encoder les entreprises
sous formes de vecteurs.
Pour rappel, l’objectif est de représenter les entreprises comme des vecteurs sémantiques pour pouvoir
les comparer rapidement à une requête.
On souhaite donc que les vecteurs encodent les informations qui permettent de décrire une entreprise comme son nom,
ses marques, ses produits, éventuellement son activité, etc.
Commençons par nous intéresser aux modèles de langages.
Les modèles de langage comme Bert ou GPT sont des réseaux de neurones basés sur l’architecture Transformer. Cette architecture a été mise au point en 2017 par Google initialement pour répondre à la question de la traduction automatique. L’innovation principale du Transformer est l’attention (ou plutôt la self-attention). Il s’agit d’un type de couche de réseaux de neurones qui permet de déterminer les relations entre les différents mots d’une phrase. Ainsi, le Transformer est capable de « comprendre » les mots en fonction de leur contexte d’utilisation dans une phrase.
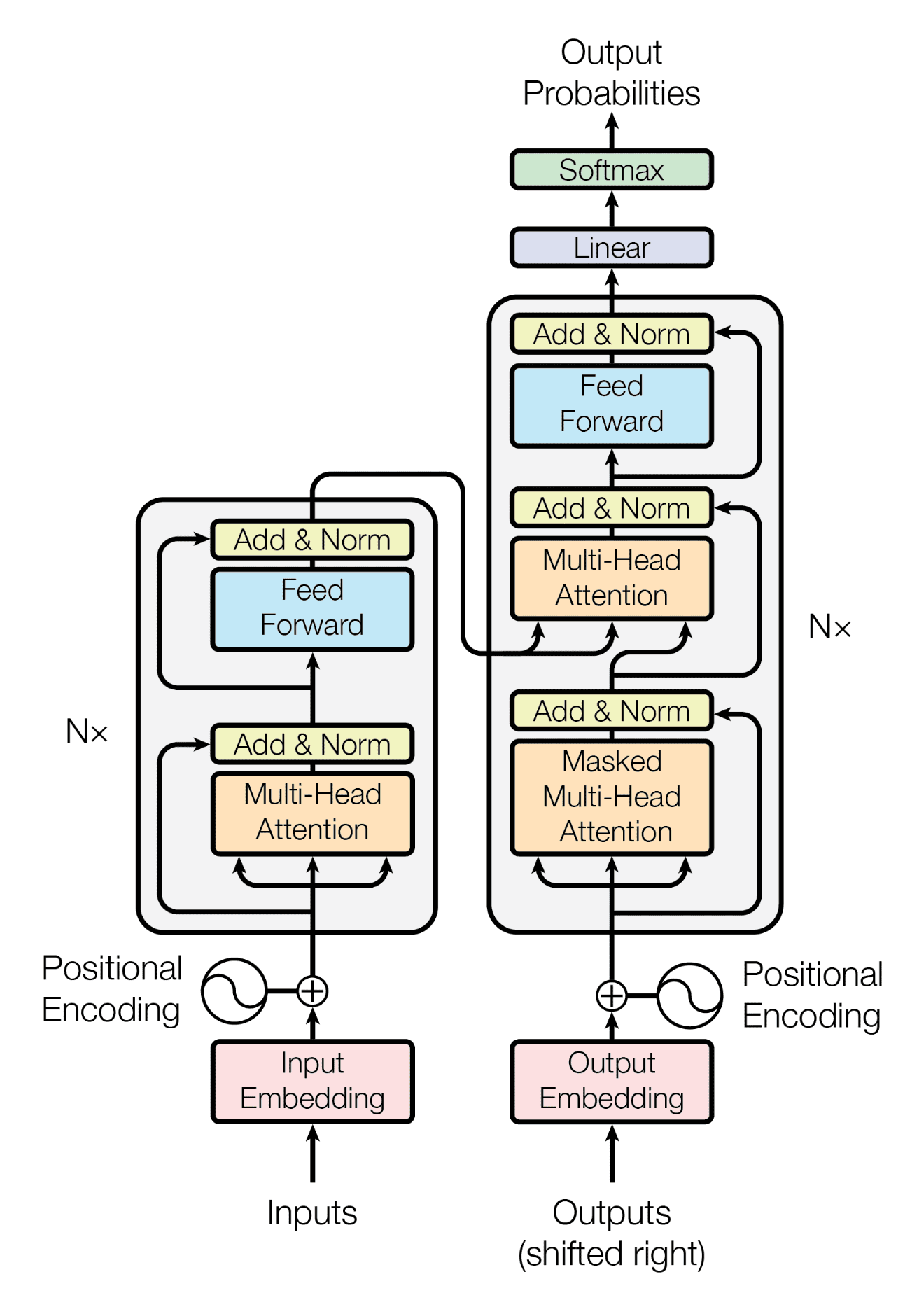
La raison de la supériorité du Transformer par rapport aux autres architectures de réseaux de neurones (comme les réseaux convolutionnels pour les images ou les réseaux récurrents pour le texte) n’est pas parfaitement comprise. Cependant, la simplicité calculatoire de l’attention a permis de créer et d’entraîner des modèles de plus en plus grands, ce qui les a aussi rendus plus performants. Cet article rentre plus en détail sur le fonctionnement d’un Transformer.
Le transformer original était donc un modèle de traduction (rapidement mis en place par DeepL notamment), mais ce qui a vraiment permis un renouveau dans le traitement du langage, c’est l’utilisation du Transformer comme modèle de langage.
La modélisation de langage est une tâche de Machine Learning qui consiste à prédire le mot suivant à partir d’un début de phrase. C’est une tâche relativement simple, mais qui a l’énorme avantage d’être auto-supervisée. C’est-à-dire qu’il n’est pas nécessaire de créer manuellement un jeu de données labellisé pour faire l’apprentissage. En effet, n’importe quel texte peut être utilisé pour effectuer l’apprentissage et la validation en même temps. Par exemple, le modèle va prendre les 3 premiers mots d’un texte pour essayer de prédire le 4ème. Il pourra savoir instantanément si la prédiction qu’il a faite est la bonne ou non et ainsi se corriger en cas d’erreur. Ensuite il pourra prendre les 4 premiers mots pour prédire le 5ème, etc.
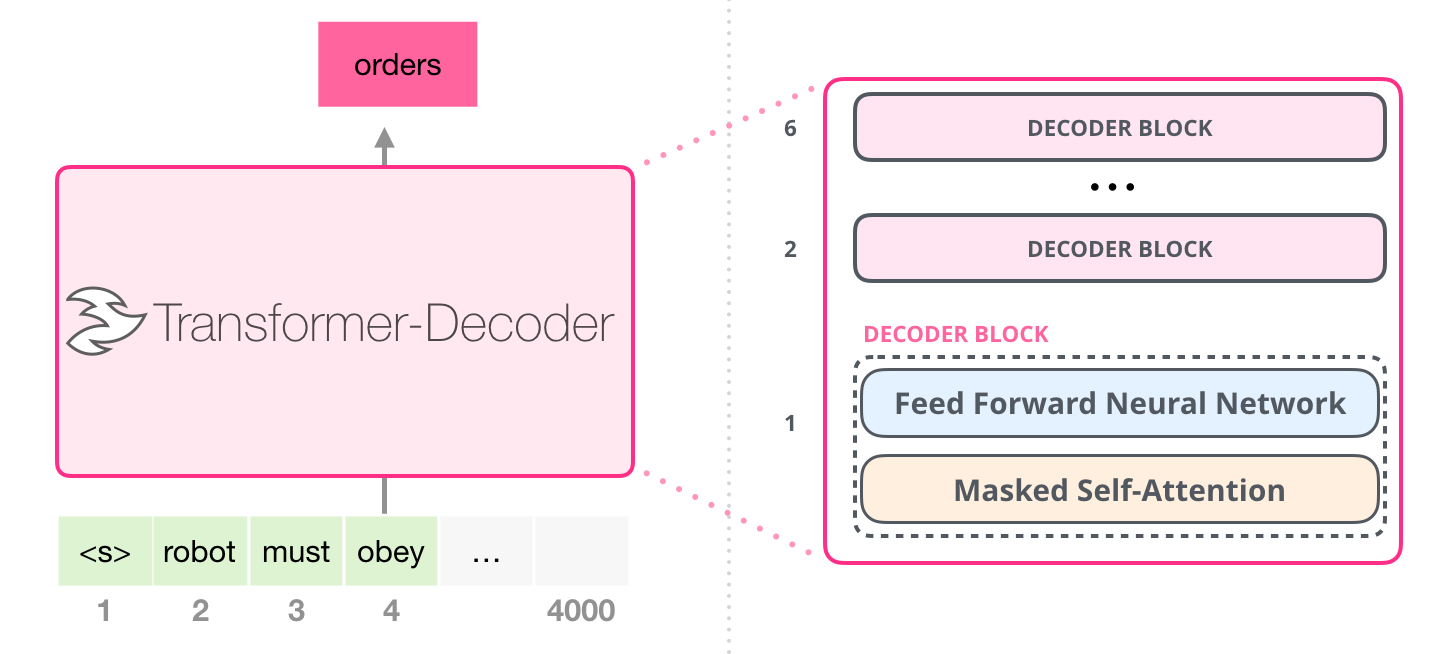
Cette tâche de modélisation de langage peut paraitre simple, mais pour pouvoir la résoudre, le modèle a besoin d’une représentation permettant la compréhension du sens des mots et du contexte de la phrase. Cette tâche force donc le modèle à apprendre à construire une représentation sémantique du texte. Une fois le modèle entraîné, il est donc capable de représenter sous forme de vecteurs contextualisés n’importe quel mot ou phrase.
Le fait que cette tâche soit auto-supervisée pour le modèle permet de l’appliquer à très grande échelle. Il est par exemple possible d’effectuer cette tâche sur l’entièreté des pages de Wikipedia. Cette abondance de données d’apprentissage combiné à l’architecture adaptée du Transformer a permis l’apprentissage de modèles de plus en plus gros et performants.
Nous venons de voir le principe de fonctionnement des modèles de langages. Mais comment les utiliser ? Il est très complexe de réaliser soi-même l’apprentissage d’un modèle de langage, car pour avoir un modèle performant, la quantité de données nécessaire est très importante. L’apprentissage d’un tel modèle peut prendre plusieurs jours, voir semaines. Heureusement, de nombreux modèles déjà entrainés sont disponibles en open source et accessibles pour tout le monde. L’ espace Models du site Hugging Face regroupe beaucoup de ces modèles catégorisées selon différents critères. Par exemple les tâches sur lesquelles ces modèles ont été entrainés, les jeux de données, les langues etc. Pour donner un ordre d’idée, il y a actuellement plus de 120 000 modèles disponibles sur cette plateforme.
Quand on veut utiliser un modèle de langage, il faut donc rechercher ceux qui correspondent à notre cas d’usage et nos contraintes techniques. Un critère très important à prendre en compte est la taille du modèle. En effet, plus le modèle est gros, plus il est performant (en général) mais plus il est complexe et lourd à utiliser. C’est pourquoi chez Sparklane nous utilisons souvent des modèles distillés qui sont des versions réduites de gros modèles tout en gardant des performances similaires. Nous avons trouvé que c’était généralement le meilleur compromis en termes de performance et de capacité d’experimentation avec le modèle.
Une fois notre modèle de langage choisi, on va être capable de représenter du texte sous forme pertinente.
Cependant, cette représentation sera généraliste.
Il va être possible de spécialiser un modèle de langage pour le rendre meilleur sur certaines tâches et/ou thématiques
particulières.
Par exemple, dans notre cas d’usage de
recherche de sociétés, le modèle de langage est utilisé pour comparer des entreprises avec une requête.
On appelle cela un calcul de similarité sémantique.
On va donc chercher à améliorer notre modèle pour cette tâche de similarité sémantique afin de spécialiser les vecteurs produits par le modèle.
Pour cela, il va falloir créer un jeu de données adapté et continuer l’apprentissage du modèle sur ce jeu de données.
On parle de fine-tuning du modèle.
Par exemple, on peut indiquer au modèle que les vecteurs de «Uber» et «Uber SAS» doivent être
très similaires, mais que les vecteurs de «Uber» et «Uber eats» doivent l’être moins.
L’idée va être de construire un jeu de données regroupant bon nombre d’échantillons comme les exemples précédents.
Grâce à cette technique, on va pouvoir encoder de la connaissance métier directement dans le modèle
et donc dans les vecteurs.
Il est clair que le volume et la qualité du jeu de données utilisé pour le fine-tuning aura un impact très important
sur le comportement du modèle.
Cette approche permet aussi de prendre en compte les erreurs du modèle.
En effet, on pourra ajouter les erreurs de notre système de recherche dans ce jeu de données et relancer
le fine-tuning du modèle pour corriger son comportement
Une fois le modèle Fine-tuné et adapté à notre tâche, il faut encoder les sociétés. Pour ce faire, plusieurs options s’offrent à nous. En effet, les sociétés sont des données structurées complexes, représentées par différents types de données textuelles, notamment le nom déclaré de l’entreprise, des noms d’usages, des marques, des adresses etc.
On pourrait imaginer encoder l’ensemble de ces informations sous la forme d’un même vecteur, cependant, on risque de perdre des informations importantes en essayant de trop en mettre dans un seul vecteur. Après avoir fait quelques expérimentations avec cette approche, nous avons décidé de représenter chaque entreprise par plusieurs vecteurs de typologies différentes. Cette approche laisse plus de possibilités pour ajuster les résultats et ajouter d’éventuelles règles manuelles. Par exemple, en ayant des vecteurs différents pour les noms d’entreprises et pour les marques, il devient possible de pondérer l’importance de ces différents axes lors de la recherche. Il ne serait pas simple de faire l’équivalent en encodant toutes les informations de l’entreprise dans un seul vecteur.
Pour l’encodage des vecteurs, on utilise la bibliothèque Sentence-Transformers adaptée comme son nom l’indique au traitement de phrases complètes.
La complexité de l’encodage des sociétés repose principalement dans la gestion de la volumétrie de vecteurs à encoder. Pour passer nos millions d’entreprises dans le modèle de langages en un temps raisonnable, des GPU sont nécessaires. À nouveau, la librairie Sentence-Transformers simplifie le chargement de notre modèle et l’encodage des vecteurs sur plusieurs GPU en parallèle.
Après avoir vu comment créer nos vecteurs, nous allons voir dans l’article suivant comment les stocker pour pouvoir effectuer la recherche de manière optimisée.
Série d'articles sur la recherche d'entreprise
- Introduction
- Sélection des candidats (Retrieval)
- Scoring des candidats
- Conclusion