

Recherche sémantique d'entreprises
Dans cette série d’articles, nous allons nous intéresser aux enjeux et aux problématiques de la mise en place d’un système de recherche sur un grand volume de données à l’aide des technologies récentes de Deep Learning.
Une des thématiques techniques centrale chez Sparklane est la capacité à identifier une entreprise inscrite au registre des entreprises à partir d’informations variées, parcellaires et souvent imparfaites, comme un nom d’usage, une URL, une adresse, etc. D’un point de vue technique, on peut rapprocher cela à la recherche de pages Web en fonction d’une requête utilisateur ou même d’un système de recommandation.
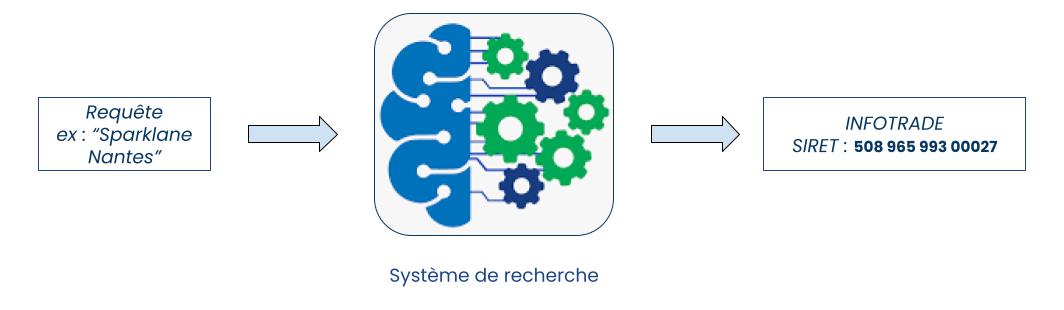
Il est assez classique de résoudre ce genre de problème en le découpant en deux étapes.
- Retrieval: une première étape pour récupérer une liste de réponses candidates. On parle en général de retrieval stage en anglais.
- Scoring/Ranking: une seconde étape de tri (ou scoring/ranking) pour déterminer la ou les réponses optimales parmi la liste de candidats sélectionnés.

L’intérêt de procéder en deux phases est de pouvoir répondre à la problématique en un temps acceptable. En effet, la phase de recherche (retrieval) de candidats prend en compte l’entièreté de la base de données, qui peut souvent contenir plusieurs millions d’entrées sur ce genre de problématique (voire beaucoup plus). Elle doit donc être implémentée de manière relativement simple, pour permettre de filtrer rapidement ce qui peut être mis de côté. Cette phase renvoie en général de quelques dizaines à quelques milliers d’élements candidats (des sociétés dans notre cas). L’étape de scoring s’exécutant sur un nombre beaucoup plus restreint d’échantillons peut être plus complexe d’un point de vue calculatoire et être plus précise. En général, cette étape prend en compte un grand nombre de critères afin d’obtenir la meilleure pertinence possible.
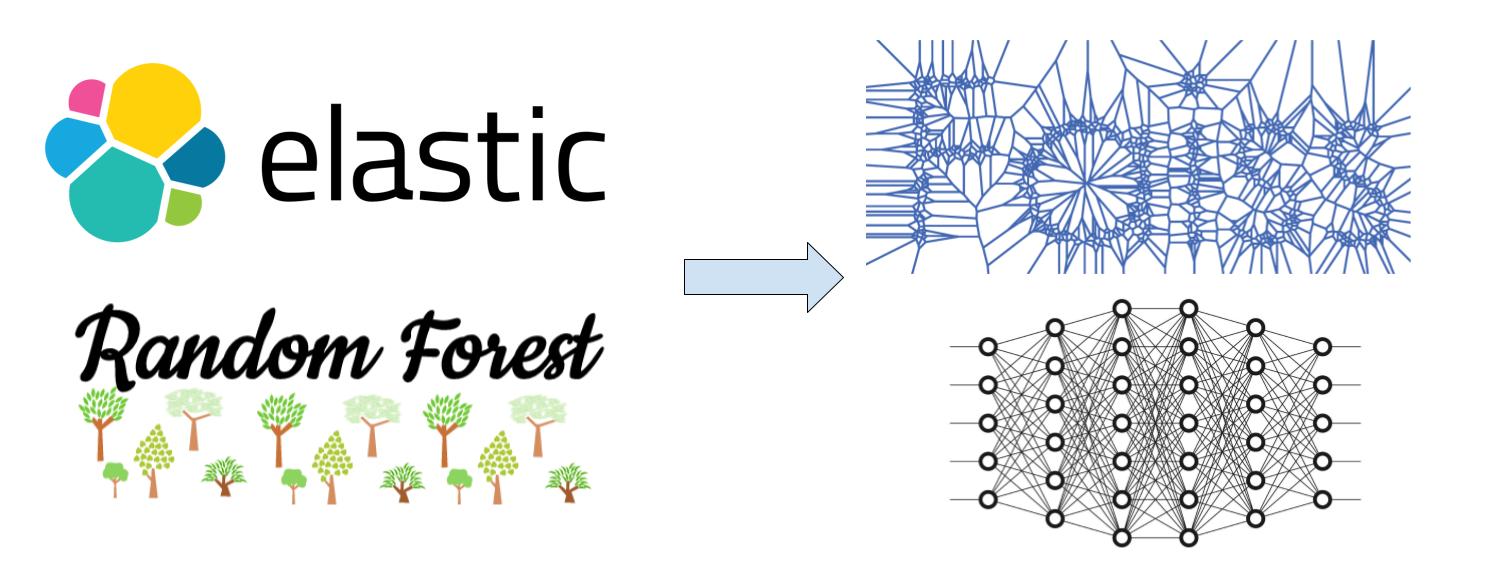
Historiquement chez Sparklane, la brique permettant de résoudre ce problème était basée sur une requête ElasticSearch pour l’étape de selection des candidats, suivie d’un modèle de Machine Learning, plus précisément un Random Forest pour le scoring. Cette approche fonctionnait bien, mais rendait complexe la mise à jour des données. De plus, certaines entreprises passaient parfois entre les mailles du filet à cause de la requête ElasticSearch et la correction de ces erreurs était difficile.
Nous avons donc pris la décision d’étudier la possibilité d’une refonte de ce système.
Un des objectifs de cette refonte était de se baser sur les approches récentes de réseaux de neurones
pour tirer parti de leur capacité de représentation du texte.
On parle ici de modèles de langages basés sur des transformers comme BERT ou GPT.
En effet, avec les différentes démonstrations mises en avant par des entreprises comme OpenAI (GPT3, Chat-GPT)
ou Google/Deepmind (PaLM, Flamingo), les possibilités offertes par les gros modèles de langages
(appelés modèles de fondations par certains) semblent très prometteuses.
La question qui s’est posée était donc :
Est-il possible de tirer parti des capacités de ces modèles au sein d’un environnement
avec des contraintes techniques fortes pour en faire un produit viable ?
Dans cette série d’articles, nous allons discuter de cette nouvelle approche, des difficultés de sa mise en place, de ses avantages, mais aussi de ses inconvénients par rapport à l’approche initiale. Comme on dit « There is no such thing as a free lunch ».
Nous allons commencer par nous intéresser dans l’article suivant à la premiere étape : la sélection des candidats (Retrieval)
Série d'articles sur la recherche d'entreprise
- Introduction (ce poste)
- Sélection des candidats (Retrieval)
- Scoring des candidats
- Conclusion