
Sélection des candidats
Cet article fait partie d’une série d’articles sur la recherche dans de gros volumes de données à travers l’utilisation des technologies récentes de Deep Learning. Introduction de la série.
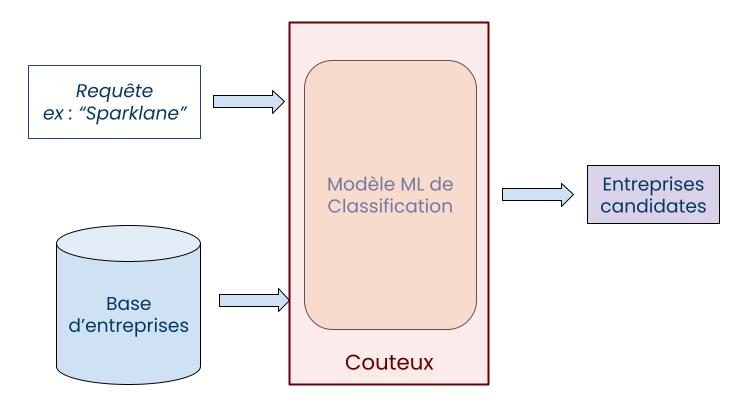
Comme évoqué dans l’introduction, l’objectif de cette étape est de filtrer le grand nombre d’éléments présents dans la base de données pour en extraire un nombre réduit de candidats intéressants. Dans notre cas d’usage, on va donc chercher à identifier les entreprises qui semblent les plus pertinentes par rapport à une requête spécifique (qui peut contenir un nom d’entreprise, une URL, une adresse, etc.).
L’idée que nous tentons de mettre en oeuvre est de profiter des capacités des modèles de langage et du Deep Learning pour remplacer l’utilisation du moteur de recherche ElasticSearch.
Mais comment peut-on les exploiter de manière pertinente ?
Comme les modèles de langage sont des modèles de Machine Learning, l’approche la plus immédiate serait de représenter cette étape de filtrage comme un problème de classification supervisée. On pourrait ainsi prédire pour chaque entreprise si elle peut être un candidat pertinent ou non en fonction de la requête. Le souci de cette approche est qu’il faut appliquer le modèle sur l’ensemble des entreprises du datalake à chaque requête. Pour notre cas d’usage, cela correspondrait à plusieurs millions d’entreprises. Ce n’est pas vraiment viable si l’on veut garder des temps de réponses corrects. D’autant plus si notre modèle est basé sur un gros modèle de langage.
Il n’est donc pas vraiment adapté d’appliquer ces modèles de langage sur des gros volumes de données pour sélectionner
les candidats lorsqu’une requête arrive.
Par contre, il est tout à fait possible de les utiliser en mode hors-ligne afin de simplifier au maximum
la prise de décision au moment de la requête.
Avec les modèles de langage, nous allons pré-calculer des représentations des entreprises du datalake
que l’on pourra ensuite comparer facilement avec la requête.
Ces modèles sont justement très performants pour construire des représentations de texte qui encodent la sémantique (le sens).
Ainsi, en utilisant un modèle de langage, il devient possible d’obtenir une représentation sous forme de vecteur
de chaque entreprise.
Chaque vecteur encode de manière conceptuelle les informations qui nous intéressent
(par exemple le nom de l’entreprise, ses différentes dénominations, ses marques, etc.).
Nous verrons plus en détail dans l’
article suivant
le fonctionnement des modèles de langage et comment ils permettent de calculer ces representations pertinentes du texte.
Toutes nos entreprises sont donc encodées sous forme de vecteurs.
Lorsqu’une requête arrive, elle va être encodée de manière similaire afin de pouvoir être comparée
aux vecteurs des entreprises.
Cette étape ne peut pas être pré-calculée, mais comme il n’y a que la requête à encoder,
cela peut être fait en temps réel sans problème (si l’on a le hardware adéquat, on y reviendra plus tard).
On dit qu’on encode la requête dans le même espace vectoriel que les entreprises.
Ainsi, la distance entre deux vecteurs dans cet espace représente la similarité de sens entre deux entités encodées.
Les vecteurs d’entreprises qui ressemblent le plus au vecteur de la requête seront les candidats.
Cette approche s’appelle donc la recherche par similarité de vecteur ou recherche du plus proche voisin
(Nearest Neighbour Search en anglais).
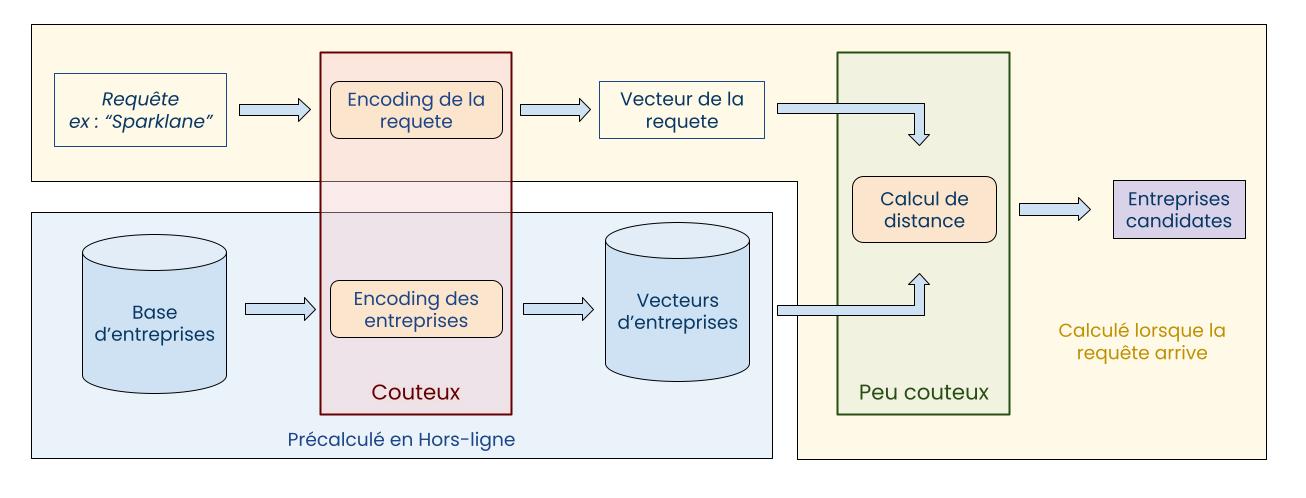
La comparaison du vecteur de la requête avec les vecteurs des entreprises est très simple d’un point de vue calculatoire (c’est souvent un produit scalaire) et donc peut-être réalisée rapidement à grande échelle.
Avec cette approche, on peut voir que l’« intelligence » et la complexité se situent plutôt dans la façon d’encoder les entités sous forme de vecteur que dans la recherche en elle-même. Cependant, avec les volumétries en jeu, la comparaison du vecteur de la requête avec les vecteurs des entreprises n’est en pratique pas si évidente. En effet, le calcul de similarité entre les vecteurs est simple et peu coûteux, mais appliqué sur plusieurs millions de vecteurs, le temps de réponse devient trop long. On va donc devoir mettre en place des approches pour ne pas avoir à effectuer le calcul sur l’ensemble des vecteurs.
Dans la suite de cette série, nous allons donc étudier plus en détail les deux briques principales évoquées dans cet article, à savoir:
Article suivant : L’encoding des entreprises
Série d'articles sur la recherche d'entreprise
- Introduction
- Sélection des candidats (Retrieval) (ce poste)
- Scoring des candidats
- Conclusion